
ScrAPI MCP サーバー
ScrAPIを使用して Web ページをスクレイピングするための MCP サーバー。
ScrAPI は、あらゆる Web サイトから簡単にデータを抽出するための強力で信頼性が高く、使いやすい機能を提供する究極の Web スクレイピング ソリューションです。
ツール
scrape_url_html- ScrAPIサービスを使用してURLからウェブサイトをスクレイピングし、結果をHTML形式で取得します。ボット検出、キャプチャ、位置情報制限などによりアクセスが困難なウェブサイトのコンテンツをスクレイピングする場合に便利です。結果はHTML形式で取得されるため、高度な解析が必要な場合に最適です。
- 入力:
url (文字列) - 戻り値: URLのHTMLコンテンツ
scrape_url_markdown- ScrAPIサービスを使用してURLからウェブサイトをスクレイピングし、結果をMarkdown形式で取得します。ボット検出、キャプチャ、位置情報制限などによりアクセスが困難なウェブサイトコンテンツのスクレイピングに使用できます。結果はMarkdown形式で取得されるため、ウェブページの構造情報ではなくテキストコンテンツが重要な場合に適しています。
- 入力:
url (文字列) - 戻り値: URLのMarkdownコンテンツ
設定
APIキー(オプション)
オプションで、 ScrAPI Web サイトから API キーを取得します。
API キーがない場合、同時呼び出しは 1 回に制限され、1 日あたり 20 回の無料呼び出しと最小限のキュー機能しか利用できなくなります。
クラウドサーバー
ScrAPI MCP サーバーは、 https://api.scrapi.dev/sseの SSE 経由のクラウドでも利用できます。
クラウドMCPサーバーはまだ広くサポートされていませんが、独自のカスタムクライアントから直接アクセスしたり、 MCP Inspectorを使用してテストしたりすることができます。現在、クラウドMCPサーバーへの接続時にAPIキーを渡す機能はありません。
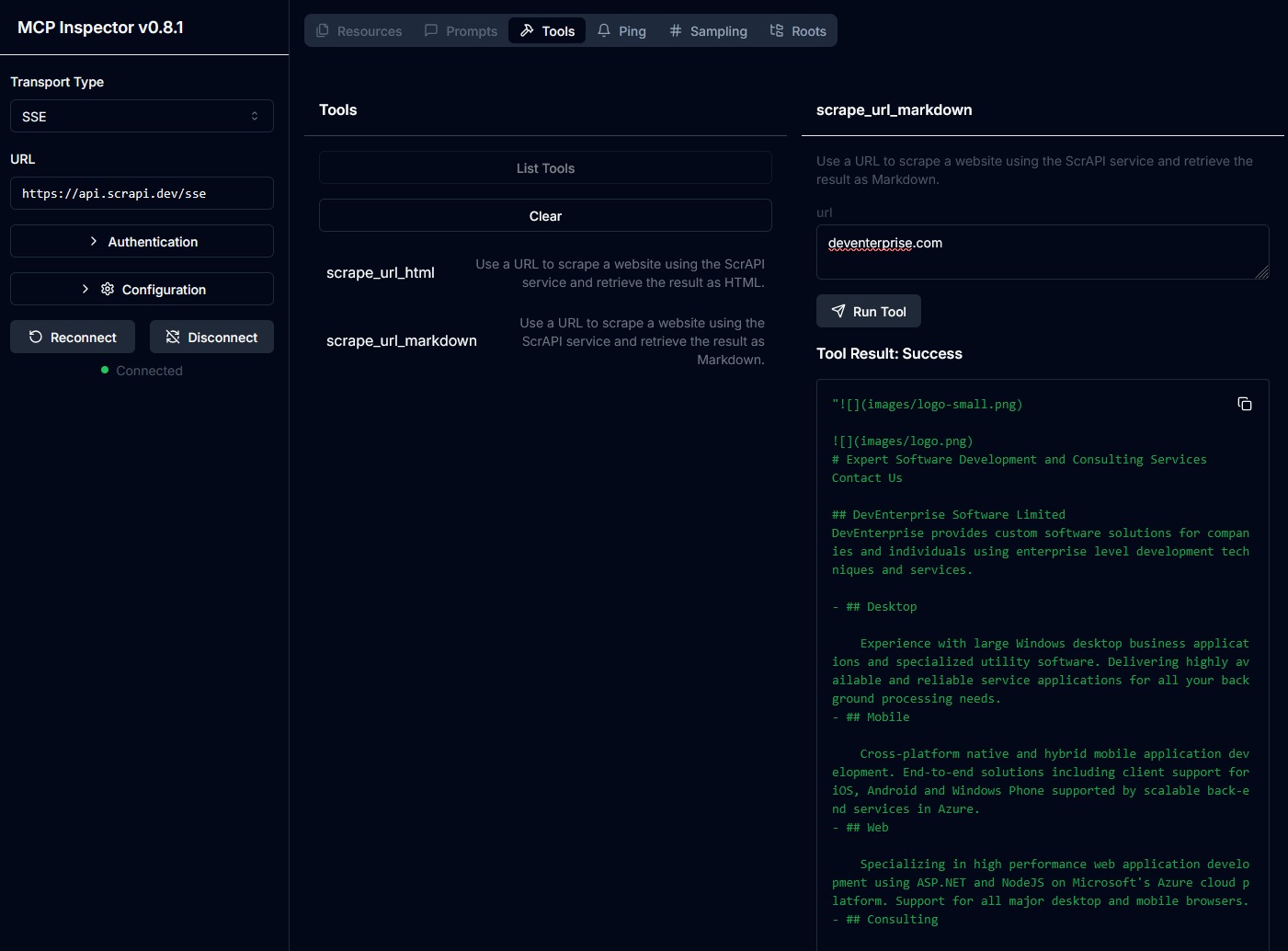
Claude Desktopでの使用
claude_desktop_config.jsonに以下を追加します。
ドッカー
{
"mcpServers": {
"scrapi": {
"command": "docker",
"args": [
"run",
"-i",
"--rm",
"-e",
"SCRAPI_API_KEY",
"deventerprisesoftware/scrapi-mcp"
],
"env": {
"SCRAPI_API_KEY": "<YOUR_API_KEY>"
}
}
}
}
NPX
{
"mcpServers": {
"scrapi": {
"command": "npx",
"args": [
"-y",
"@deventerprisesoftware/scrapi-mcp"
],
"env": {
"SCRAPI_API_KEY": "<YOUR_API_KEY>"
}
}
}
}
建てる
Dockerビルド:
docker build -t deventerprisesoftware/scrapi-mcp -f Dockerfile .
ライセンス
このMCPサーバーはMITライセンスに基づいてライセンスされています。つまり、MITライセンスの条件に従って、ソフトウェアを自由に使用、改変、配布することができます。詳細については、プロジェクトリポジトリのLICENSEファイルをご覧ください。